
Logged In or Logged Out: Do AI Platforms Choose Different Brands to Recommend?

We ran 1,530+ prompts across ChatGPT, Gemini and Perplexity in both authenticated and anonymous sessions. Here’s what the latest LLM research found.
There is an assumption quietly spreading through marketing teams right now: that AI personalises its recommendations based on who the user is. Log into ChatGPT, and surely it learns your preferences, your history, your context and recommends accordingly. Stay anonymous, and you get something more generic.
It sounds completely logical. But is it true?
We decided to find out. In the largest LLM research study we have run to date, AdLift and Tesseract submitted 1,530+ identical prompts to ChatGPT, Gemini and Perplexity simultaneously, once in a logged-in authenticated session and once in a logged-out anonymous session, across six industries and hundreds of brand comparisons.
The headline finding was an average Overlap Coefficient of 90.4%. In plain English: nine out of ten brands recommended to a logged-in user were also recommended to an anonymous one. Login state barely moves the needle on which brands AI recommends. What it does change, sometimes quite dramatically, is everything else.
We ran 1,530+ prompts across ChatGPT, Gemini and Perplexity. Here is what we found.
The question at the centre of this LLM research study 2026 is one that should matter to every brand thinking seriously about AI visibility: does an AI recommendation system behave differently depending on whether the user is identified or anonymous?
To answer it, we ran a controlled study across six industries: Insurance, Healthcare, E-Commerce, Travel and Hospitality, SaaS and B2B. These cover a wide range of consumer and business purchase decisions. For each industry, we built a curated brand dictionary and ran structured prompts covering general best-of queries, price-sensitivity queries, service-specific queries and demographic-targeted queries.
Every single prompt was submitted twice, at the same time: once by an authenticated user and once by an anonymous one. Responses were recorded verbatim. Brand mentions were extracted using whole-word pattern matching. The result was 1,530+ paired observations to work through.
We measured brand consistency using the Overlap Coefficient, which is simply the proportion of brands in the smaller response that also appear in the larger one. A score of 100% means every brand named to a logged-in user was also named to an anonymous one. Across all sectors and all three platforms, that average landed at 90.4%.

That number is the core finding of this large language model research. But the detail underneath it, broken down by sector and by platform, is where things get genuinely interesting.
Before the results: how do AI platforms actually choose which brands to recommend?
To make sense of what we found, you need a working understanding of how large language models work at the most practical level for marketers.
LLMs are not search engines. They do not look your brand up in real time and check its latest reviews or its current ad spend. They were trained, at a fixed point in time, on enormous quantities of web content: articles, reviews, forums, product pages, news coverage, research papers and more. The brand recommendations they produce are a function of what appeared in that training data, how often, in what context and with what authority around it.
This is the core reason why an AI recommendation system is unlikely to change its brand outputs based on whether a user happens to be logged in. The model’s underlying knowledge, the weights built up during training, does not update between sessions. A logged-in user might get a slightly more structured or contextualised response. But the brand hierarchy the model has learned from training data is not going to shift based on session state.
There is one important nuance worth flagging. Perplexity, unlike ChatGPT and Gemini, uses retrieval-augmented generation, meaning it searches the live web to supplement its responses. This means its outputs can include more current sources and citations. But even here, as the data shows, the core brand set stays highly consistent across session states.
The practical implication, before we even get to the numbers, is this: if you want to change what brands an AI recommends, you need to change what the model has learned, not try to optimise for the session.
What do the latest LLM research findings actually tell us about login state?
Across 1,237 paired observations where both logged-in and logged-out responses were available, the average Overlap Coefficient (OC) sits at 90.4%. That is the headline from this latest LLM research. But it is worth pausing on what it actually means before moving on.
An OC of 90.4% means that across thousands of individual brand mentions, pulled from responses generated by three different AI platforms across six completely different industries, the core set of brands recommended to an authenticated user and an anonymous user is structurally the same. This is not a rounding error or a marginal result. It is a meaningful finding about how AI brand recommendation behaviour actually works.
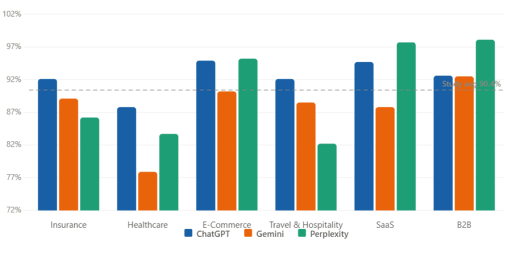
Here is how each sector breaks down:
The sectors with the highest overlap, B2B and E-Commerce, are dominated by a small number of globally recognised brands: AWS, Azure, Microsoft, Google Cloud, Apple, Samsung. These names are so deeply embedded in training data that session-level variation cannot displace them. The sectors with lower overlap, Healthcare in particular, have more complex brand landscapes where supplementary providers show more variability between sessions.
But even 83.2%, the lowest sector average in the study, is a genuinely strong consistency score. The core recommendations are stable. What shifts is the margin around them.
If the brands stay the same, what exactly does change between logged-in and logged-out?
If the brands stay largely the same, the data still surfaces something worth paying attention to. The way AI platforms respond to logged-in versus logged-out users differs meaningfully in terms of length, structure, emphasis and in one case, access to content altogether.
Response length shifts, sometimes quite dramatically
The most immediately visible difference between logged-in and logged-out responses is how long they are. But there is no single consistent direction here. The pattern varies by platform and by sector in ways that reveal something about each platform’s underlying logic.
ChatGPT produces longer responses for anonymous users in some sectors, Insurance up 5.8% and SaaS up 7.7%, but notably shorter ones in others. Healthcare responses shrink by 32.9% when the user is logged out, and B2B responses shrink by 26.9%. The pattern suggests ChatGPT adds contextual depth in its logged-in mode for complex or sensitive topics, while defaulting to broader coverage for anonymous users on more consumer-facing queries.
Gemini tends to move in the opposite direction across most sectors, consistently expanding for anonymous users. B2B responses grow by 24.7% logged-out, E-Commerce by 15.4% and SaaS by 13.7%. Its anonymous responses read as more generalist and context-setting, while logged-in responses are more tightly formatted and specific.
Perplexity is the most directionally consistent of the three: its logged-out responses are shorter across five of the six sectors. The SaaS compression is the single most striking data point in this whole LLM case study. Logged-out responses are 54% shorter on average in that sector. And yet the brand overlap still comes in at 97.7%, the highest single platform-sector score in the entire study. Response length and brand fidelity are simply not the same thing.
Brand emphasis shifts even when brand presence does not
The Overlap Coefficient measures whether a brand appears at all. What it does not capture is how prominently a brand features, specifically how many times it gets mentioned within a response. This is where the differences between sessions become more pronounced.
In Insurance, ChatGPT’s logged-out responses name every tracked brand more frequently, but the biggest gains go to challenger and niche providers. Erie is mentioned 29% more often when the user is anonymous. Liberty Mutual gains 34%. Farmers gains 39%. The anonymous response casts a wider net, surfacing brands that logged-in responses tend to keep further down the list. The core set does not change. The emphasis does.
In B2B, ChatGPT’s logged-out responses mention IBM 98% more often and Oracle 47% more, while Google Cloud loses 45% and AWS loses 19% of its mentions. Same brands. Meaningfully different weighting. For any brand in this sector, the question is not just whether you appear. It is whether you appear with the frequency that actually reflects your market position.
Perplexity’s access gap is the most significant login effect in the study
For all three platforms, login state mainly affects style and depth. In one case it affects access entirely.
In the Insurance sector, Perplexity returned 26 completely absent logged-out responses. These were prompts that received a full response in the authenticated session but returned nothing in the anonymous one. They were not random. They clustered tightly around three prompt themes: pricing queries, young driver queries and claims queries.
This is the one place in the study where authentication state materially affects content availability rather than content quality. Whether it reflects deliberate rate-limiting, content moderation logic or a retrieval constraint for commercially sensitive topics is not clear from the data alone. But the pattern is far too consistent to be coincidental. For Insurance brands whose relevance peaks on pricing or claims, the most conversion-sensitive queries in the category, anonymous users on Perplexity may simply not receive a recommendation at all.
If login state does not drive AI-powered brand visibility, what actually does?
The strategic implication of a 90.4% average Overlap Coefficient is direct: optimising for session state means optimising for the wrong variable entirely. Login personalisation is not the lever for ai brand visibility. Training-time brand salience is.
What determines whether your brand appears in ai recommendations is not who is asking the question. It is whether your brand is sufficiently embedded in the web’s information ecosystem that the model encountered it, frequently, authoritatively and in the right context, during training.
Three things actually drive AI brand recommendations in practice:
- Citation depth. How often do authoritative third-party sources reference your brand? News coverage, analyst reports, industry publications, review platforms: the more your brand appears in trusted sources, the more signal the model has to draw on when forming a response.
- Content surface area. How broad is the range of topics your brand appears alongside across the web? A brand that shows up only in its own promotional content is far less visible to an LLM than one that appears in answers to real consumer questions: comparisons, buying guides, how-to articles, expert roundups.
- Third-party validation. PR, structured data, accreditations, and review volume all play a role. LLMs learn about brands from the ecosystem that exists around them, not just from the brand’s own website—which is exactly where our LLM SEO services come in, strengthening that broader digital footprint.
The brands that score highest across all three platforms and both session states in this study are not simply the biggest names in their categories. They are the ones most deeply embedded in web discourse, the brands that appear in the content other people write about their industries. That is the quality that ai recommendations reflect.
“Your brand’s presence in AI recommendations is a structural property of your digital authority, not a function of who the user is.”
ChatGPT, Gemini and Perplexity each behave differently, but which differences actually matter for your brand?
One of the more practically useful findings from this llm research study is how differently the three platforms behave, not in the brands they select, but in their response characteristics. Understanding these platform personalities matters for how brands read their AI visibility and decide where to focus.
ChatGPT has the broadest reach and the highest overall OC
ChatGPT achieves the highest average Overlap Coefficient of the three platforms at 92.4%. Its logged-in responses tend to be more structured and citation-rich. Its logged-out responses are broader in scope. In consumer-facing sectors, anonymous users actually receive responses that surface more of the brand landscape, not less. ChatGPT’s anonymous mode reads a bit like a general industry briefing. Its logged-in mode reads more like a tailored recommendation. The brand set underlying both is nearly identical.
Gemini has the most stable formatting but the most variable OC
Gemini records the widest range of Overlap Coefficient scores across the study: 92.5% in B2B, but only 77.9% in Healthcare, which is the lowest single platform-sector score we recorded. Its logged-out responses tend to be longer and more generalist, while logged-in responses are more tightly formatted and specific. Healthcare is the clearest example of Gemini’s supplementary brand set showing sensitivity to session state. The anchor institutions are stable. The second-tier providers shift more than on any other platform.
Perplexity is citation-dense and compressed, but brand-consistent
Perplexity’s use of real-time web retrieval makes it structurally different from the other two platforms. It produces the highest citation volume of any platform when logged in, averaging 9.7 source links per response, and drops to 7.6 when the user is anonymous. Its responses are considerably shorter in anonymous mode across most sectors. And yet it achieves strong brand consistency: 90.5% average OC across the study, including the highest single score of 98.1% in B2B. The platform strips back the detail for anonymous users while preserving the brand signal almost entirely.
The platform your brand appears on matters a great deal more than the session state the user is in. Perplexity users see shorter responses but the same brands. Gemini users see slightly more variability in the supplementary set. ChatGPT users see largely the same brands regardless. Login state is genuinely the least interesting dimension here.
Is AI recommending your brand right now, and what should you do if it is not?
Login state is not the lever for ai powered brand visibility. This llm research study makes that clear across 1,530+ observations, six industries and three platforms. The brands that appear consistently, to logged-in and anonymous users alike, are the ones whose digital authority is structural rather than circumstantial.
That means the actionable questions look different from what most brands are currently asking:
Are you cited in the authoritative sources that LLMs are trained on? Does your content appear in the contexts where buying decisions are actually being researched? Are third parties writing about your brand with the depth and frequency that signals genuine market leadership? Are you tracking your ai brand visibility across platforms as an ongoing programme rather than a one-off snapshot?
LLMs update. Brand rankings shift over time. A one-time audit tells you where you stand today. A monitoring programme gives you a competitive edge as the landscape evolves.
AdLift a leading digital marketing agency in USA, provides the strategy: the SEO, content and PR programmes that build the citation footprint that makes ai brand visibility possible in the first place. Tesseract provides the infrastructure: real-time LLM brand monitoring, Overlap Coefficient tracking and AI visibility intelligence across all three platforms.
